ChromaDB: Open-Source Vector Database
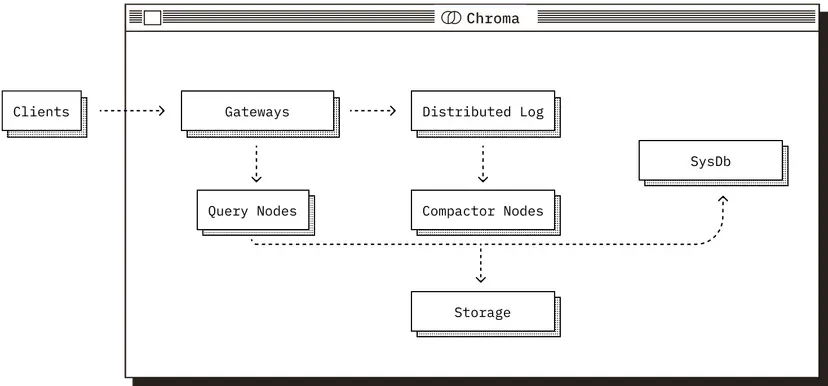
Introduction
ChromaDB is a lightweight, embeddable vector store that simplifies working with high-dimensional data like text embeddings. It enables efficient similarity searches without the overhead of full databases, making it suitable for prototypes to production. Key use cases include chatbots, recommendation systems, and knowledge bases for LLMs. Unlike traditional databases, it focuses on vector operations with automatic embedding generation.
What is ChromaDB?
ChromaDB is an open-source database for vector embeddings, allowing storage and retrieval based on semantic similarity.
Key Features:
- Simple API for creating collections, adding/querying data.
- Automatic embeddings using models like Sentence Transformers.
- Support for metadata filtering, full-text search, and multi-modal data.
- Scalable: In-memory, persistent disk storage, or client-server mode.
- Integrations: LlamaIndex, Hugging Face, OpenAI.
- Free and community-driven, with no strict dependencies on cloud services.
Advantages:
- Fast setup and queries for small to medium datasets.
- Customizable embeddings for domain-specific accuracy.
- Handles updates, deletes, and persistence easily.
Considerations:
- For massive scale, pair with backends like ClickHouse.
- Requires compatible SQLite (3.35+) for DuckDB backend.
- Embeddings must match dimensions within a collection.
Installation
Install ChromaDB via pip3. For custom embeddings, add providers like OpenAI or Sentence Transformers.
Basic Installation:
pip3 install chromadbWith Extras (e.g., for OpenAI embeddings):
pip3 install chromadb openai sentence-transformersVerification:
import chromadb print(chromadb.__version__) # Example output: 0.5.5Notes: Ensure Python 3.8+ (3.11 recommended). For GPU-accelerated embeddings, install relevant libraries like
torch. No internet needed post-install, but some models download on first use.
Core Concepts
Following is the Chroma Tenancy and DB Hirerarchy:
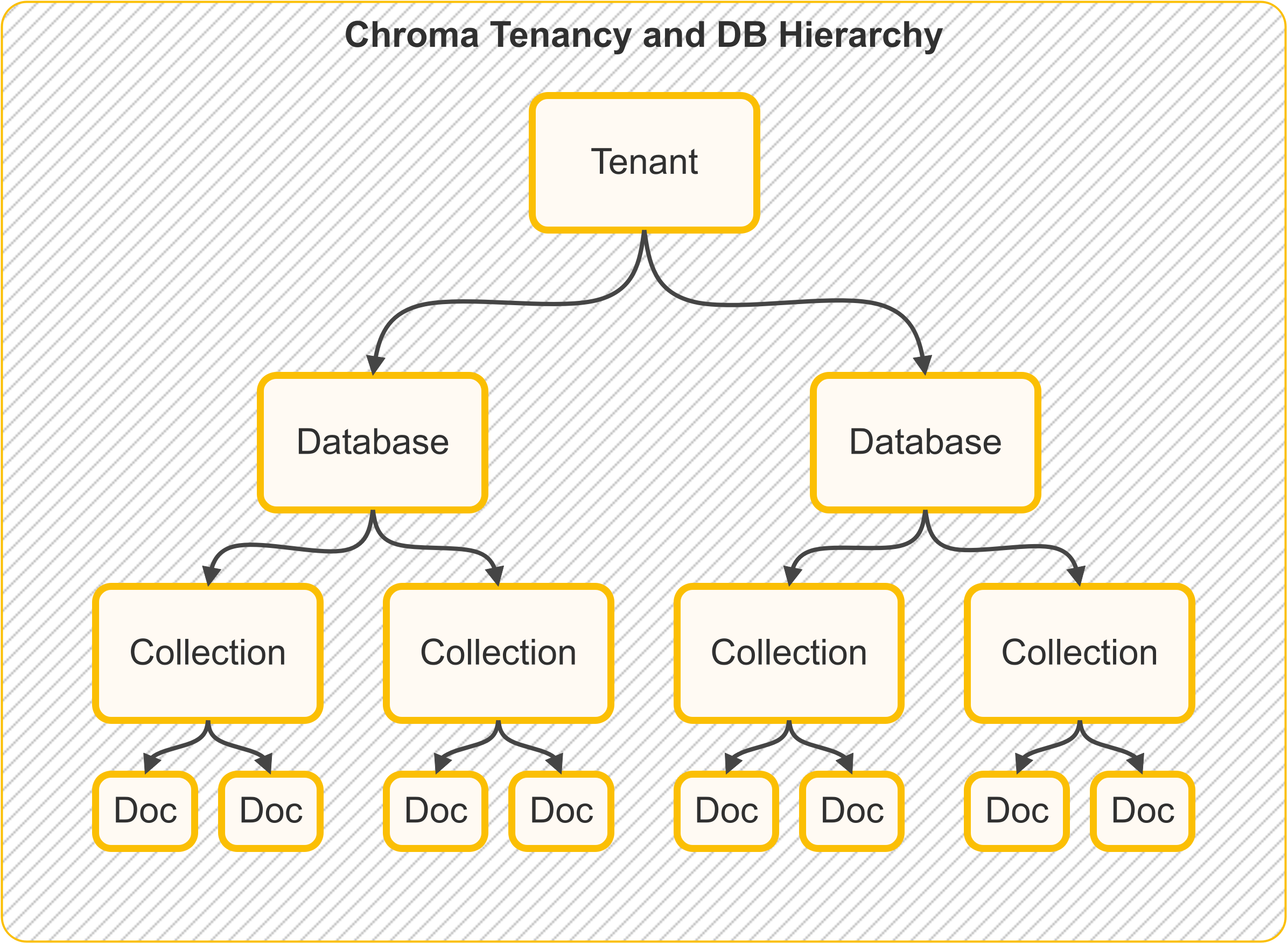
Client: Entry point for database interactions.
- In-memory: Temporary, for testing.
- Persistent: Saves to disk.
- HTTP: For client-server setups.
Collection: Container for embeddings, like a table. Stores documents, embeddings, metadata, and IDs.
Embeddings: Numerical vectors representing data. Generated automatically or provided externally.
Documents: Raw data (e.g., text strings) to embed.
Metadata: Dictionaries for filtering (e.g., {“source”: “wiki”}).
IDs: Unique strings for items.
Querying: Semantic search with options for filters, distances (e.g., cosine).
Common Variables:
name: Collection identifier (string).n_results: Number of query results (int, default 10).where: Metadata filter (dict with operators like$eq,$and).where_document: Text content filter (e.g.,{"$contains": "word"}).
Client Types
| Client Type | Description | When to Use | Pros | Cons |
|---|---|---|---|---|
| Client() | In-memory, ephemeral. | Quick prototypes. | Fast, no disk I/O. | Data lost on restart. |
| PersistentClient | Disk-based with DuckDB + Parquet. | Persistent local storage. | Survives restarts, scalable. | Slower for massive writes. |
| HttpClient | Connects to a server. | Distributed/production. | Multi-user, remote access. | Needs server setup (e.g., Docker). |
- Example Setup:
import chromadb client = chromadb.Client() # In-memory
Embedding Functions
ChromaDB handles embeddings via functions.
Default: Sentence Transformers’
all-MiniLM-L6-v2(384 dimensions).Custom: Subclass
EmbeddingFunctionfor any model. This allows you to wrap existing functions or create new ones for custom logic, such as using a different model or preprocessing text before embedding.Providers: OpenAI, Hugging Face, Cohere, etc.
Building a Custom Function (Simple Example Wrapping Default):
from chromadb import EmbeddingFunction from chromadb.utils.embedding_functions import DefaultEmbeddingFunction class embedFunction(EmbeddingFunction): def __init__(self): super(embedFunction, self).__init__() self.dfe = DefaultEmbeddingFunction() def __call__(self, doc): return self.dfe(doc) efunk = embedFunction()Usage:
collection = client.get_or_create_collection( name="my_collection", embedding_function=efunk )Explanation of Custom Functions: The class must inherit from
EmbeddingFunctionand implement__call__, which takes input documents (list of strings) and returns embeddings (list of lists of floats). In the example above, it simply delegates to the default function, but you can add custom logic, like text cleaning or using a different model (e.g., from Sentence Transformers). Ensure the output dimensions are consistent across the collection.Using embedding_function=None: Set this when creating a collection to disable automatic embedding generation. This is useful if you always provide pre-computed embeddings manually (via the
embeddingsparameter inaddorupdate). If you try to add documents without embeddings in this mode, ChromaDB will raise an error. Example:collection = client.create_collection( name="manual_embeddings", embedding_function=None )With this, you must always include
embeddingsin operations likeaddorupdate, ensuring full control over vectors without any auto-computation.
Common Operations
Creating Collections
- Basic:
collection = client.create_collection(name="my_collection") - With Options:
collection = client.get_or_create_collection(name="my_collection", embedding_function=efunk) - With Distance Metric Configuration: Specify the similarity metric used for queries via the
configurationparameter. This configures the HNSW index. The distance metric cannot be changed after the collection is created; to switch, clone the collection. Available options: “l2” (Euclidean, default), “ip” (inner product), “cosine” (cosine distance). For text embeddings, cosine is often preferred as it handles normalized vectors well.Note: When using cosine, query distances represent cosine distance (1 - cosine similarity). To get similarity scores, compute 1 - distance.collection = client.create_collection( name="cosine_collection", configuration={"hnsw": {"space": "cosine"}} # Or "l2", "ip" )
Adding Data
- With Auto-Embedding:
collection.add( documents=["Text one", "Text two"], metadatas=[{"key": "val1"}, {"key": "val2"}], ids=["id1", "id2"] ) - With Pre-Computed Embeddings:
collection.add( embeddings=[[0.1, 0.2], [0.3, 0.4]], documents=["Doc1", "Doc2"], ids=["id1", "id2"] )
Querying
Basic Semantic Search:
results = collection.query(query_texts=["Similar text"], n_results=2) print(results["documents"]) # List of matching docsWith Filters:
results = collection.query( query_texts=["Query"], where={"source": {"$eq": "wiki"}}, where_document={"$contains": "keyword"}, include=["documents", "distances", "metadatas"] )Output Structure: Dict with
ids,documents,distances,metadatas, etc.
Updating
- Standard Update:
collection.update( ids=["id1"], documents=["New text"], metadatas=[{"updated": True}] ) - Keep Embedding Unchanged (Fetch First):
item = collection.get(ids=["id1"], include=["embeddings"]) collection.update( ids=["id1"], documents=["New text"], embeddings=item["embeddings"] ) - Upsert (Insert if New):
collection.upsert(ids=["new_id"], documents=["New doc"])
Deleting
- By ID:
collection.delete(ids=["id1"]) - By Filter:
collection.delete(where={"source": "old"})
Management
- List Collections:
client.list_collections() - Delete Collection:
client.delete_collection(name="my_collection") - Count Items:
collection.count() - Peek:
collection.peek()(First few items)
Persistence and Deployment
- Configuring Persistence with Settings: Use
Settingsto customize client behavior, such as enabling resets or specifying a persistence directory. This allows for flexible, disk-based storage.from chromadb.config import Settings settings = Settings(allow_reset=True, persist_directory="./chroma") client = chromadb.Client(settings=settings) - Persist Changes: Auto in persistent clients; manual via
client.persist(). - Server Mode:Client:
docker pull chromadb/chroma docker run -p 8000:8000 chromadb/chromachromadb.HttpClient(host="localhost", port=8000) - Backups: Copy persist_directory or use cookbook recipes.
- Multi-Tenancy: Add auth plugins for production.
Full Example Workflow
import chromadb
client = chromadb.Client()
collection = client.create_collection("example")
# Add
collection.add(documents=["Apple is a fruit.", "Banana is yellow."], ids=["1", "2"])
# Query
results = collection.query(query_texts=["What color is banana?"], n_results=1)
print(results["documents"][0][0]) # "Banana is yellow."
# Update
collection.update(ids=["2"], documents=["Banana is a fruit."])
# Delete
collection.delete(ids=["1"])Conclusion
In summary, ChromaDB stands out as a versatile and efficient open-source vector database, simplifying the management of embeddings for AI-driven applications. Its intuitive API, support for custom integrations, and scalability from local prototypes to production environments make it an essential tool for developers building semantic search, RAG systems, and beyond. With ongoing community contributions, ChromaDB continues to evolve, enabling faster innovation in the world of vector data handling.